



Hay o No AI 🥸
Inteligencia artificial y algunas realidades a las que debemos despertar

Hay mucho qué reflexionar, hablar y, especialmente, especular sobre inteligencia artificial. La conversación de hoy es un llamado a despertar a las realidades de un nuevo paradigma, sin necesidad de hacer futurología.
Comencemos.

Uno de los mejores análisis que he leído sobre el estado actual de la inteligencia artificial y su futuro es el paper Situational Awareness de Leopold Aschenbrenner, recientemente despedido de OpenAI, publicado en junio de este año. Son 165 páginas de análisis utilizando información de fuentes públicas que concluyen que la inteligencia artificial general (AGI) es factible para finales de 2027.
En las primeras páginas aparece este párrafo:
[…] los puntos de referencia más difíciles sin resolver son pruebas como GPQA, un conjunto de preguntas de biología, química y física a nivel de doctorado. Muchas de las preguntas me parecen incomprensibles, y hasta los doctores en otras áreas científicas, después de pasar más de 30 minutos con Google, apenas obtienen un puntaje por encima del azar. Claude 3 Opus actualmente obtiene alrededor del 60%, en comparación con los doctores en estas áreas que logran aproximadamente un 80% […].
Recuerden esto: en junio de 2024, los modelos de inteligencia artificial eran mediocres para resolver pruebas GPQA de nivel doctorado.
La semana pasada, OpenAI lanzó su más reciente modelo de inteligencia artificial. Es un LLM (large language model) bautizado “ChatGPT-o1”. La “o” es de OpenAI y el “1” indica que reiniciaron la cuenta de versiones y que éste modelo es una generación totalmente nueva.
Me ha llamado la atención que, si bien por esos días hubo algo de alboroto en algunos medios sobre el modelo, en general no causó mayor conversación en mis círculos cercanos. He estado pensando dónde está la aparente desconexión.
Repasemos qué tiene de novedoso “o1”.
Hasta hace poco, el desempeño de los LLMs era relativamente pobre en razonamiento complejo, razonamiento predictivo, matemáticas y otras capacidades en las que los seres humanos somos bastante buenos:

“o1” introduce capacidades avanzadas de razonamiento, es decir, el modelo está diseñado para imitar un proceso de pensamiento más humano y reflexivo para generar respuestas. Para lograr eso hace, principalmente, dos cosas:
Un análisis paso a paso: a diferencia de modelos anteriores que simplemente generaban respuestas rápidas basadas en patrones de lenguaje, ChatGPT-o1 se toma un tiempo adicional para analizar la pregunta y evaluar posibles respuestas. En este proceso el algoritmo descompone el problema en partes más manejables y considera diferentes formas de contestar antes de llegar a una conclusión.
Una autoevaluación: el modelo puede revisar su propia respuesta antes de presentarla. Por ejemplo, puede contar cuántas palabras hay en su respuesta o identificar elementos específicos dentro de ella, lo que demuestra un nivel de autoconsciencia en su funcionamiento que no era posible en versiones anteriores.
Conceptualmente hablando, que el modelo incorpore estas dos nuevas capacidades le permite resolver, con alto desempeño, fluidez y naturalidad, tareas mucho más complejas que requieren lógica y razonamiento matemático. Como era de esperarse, también, su capacidad para crear código de software ahora también es muy superior.
En una publicación del blog de OpenAI, la semana pasada, la empresa afirma lo siguiente:
OpenAI o1 se encuentra en el percentil 89 en preguntas de programación competitiva (Codeforces), se posiciona entre los 500 mejores estudiantes en Estados Unidos en una clasificatoria para la Olimpiada Matemática de EE.UU. (AIME), y supera la precisión a nivel de doctorado en humanos en un conjunto de problemas de física, biología y química (GPQA).
Comparativamente hablando, esto se ve así:
, Code (CodeForces), and PhD-Level Science Questions (GPQA Diamond)")
El avance es descomunal. Me llama especialmente la atención que las mayores ganancias son en esos puntos débiles que veíamos en la gráfica de arriba, precisamente por la complejidad de simular el razonamiento humano.
Para poner en perspectiva lo anterior: GPT-4o es un poco mejor en desempeño, 50% más rápido y 6x más barato que GPT-4. Ahora miremos a GPT-4 con respecto a los otros modelos existentes:
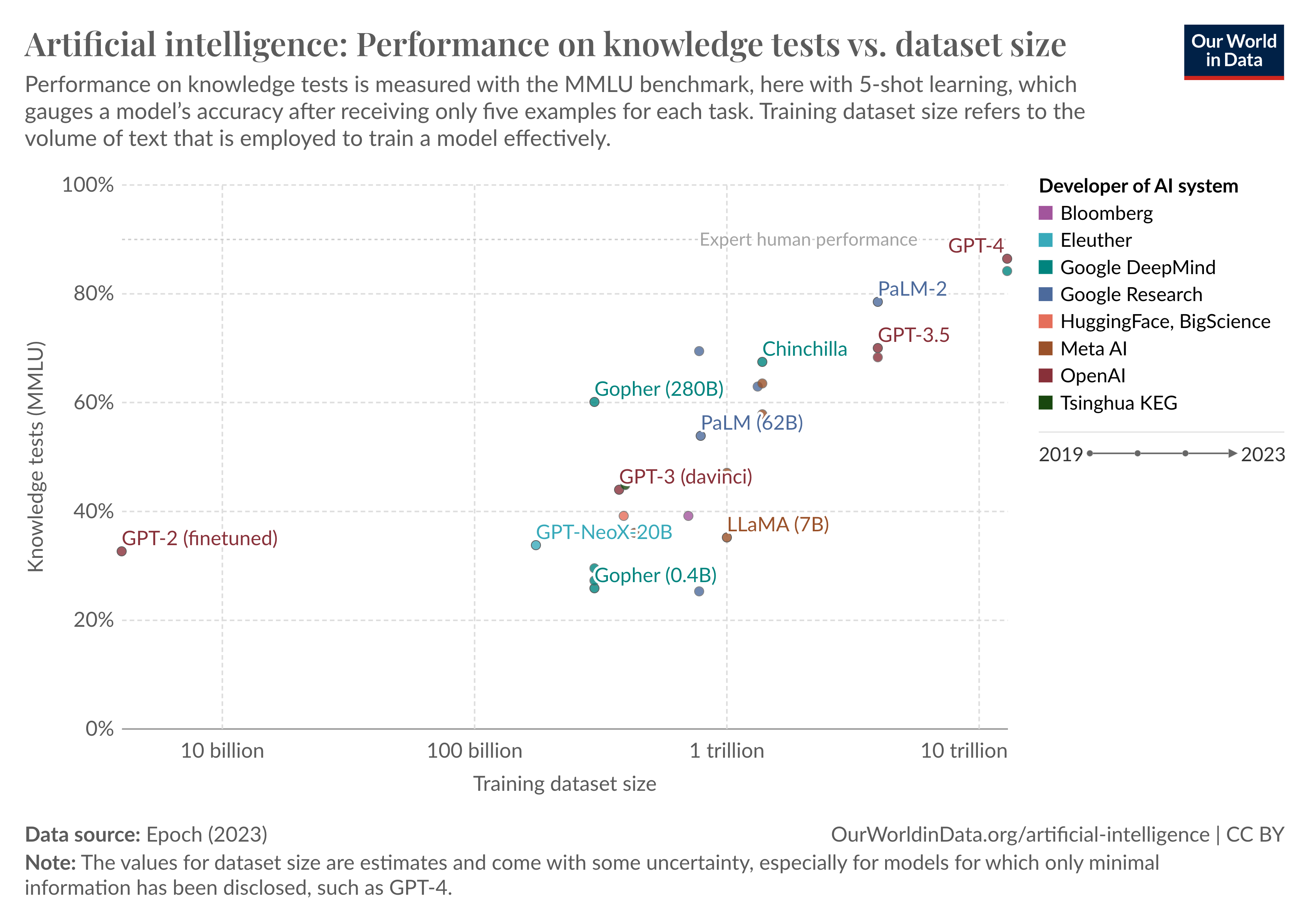
Según Papers With Code:
MMLU (Comprensión de Lenguaje Multitarea Masiva) es un nuevo punto de referencia diseñado para medir el conocimiento adquirido durante el pre-entrenamiento, evaluando modelos exclusivamente en configuraciones de zero-shot y few-shot. Esto hace que el punto de referencia sea más desafiante y más similar a cómo evaluamos a los humanos. El punto de referencia abarca 57 temas a través de las áreas de STEM, humanidades, ciencias sociales y más. Su dificultad varía desde un nivel elemental hasta un nivel profesional avanzado, y evalúa tanto el conocimiento general del mundo como la capacidad para resolver problemas. Los temas van desde áreas tradicionales, como matemáticas e historia, hasta áreas más especializadas como derecho y ética. La granularidad y amplitud de los temas hace que este punto de referencia sea ideal para identificar los puntos ciegos de un modelo.
En resumen, la gráfica anterior nos muestra qué modelo es mejor bajo una métrica estándar llamada MMLU. Si bien no está anotado allí, GPT-3 era tan inteligente como un estudiante de nivel elemental y GPT-4 como uno muy bueno de secundaria.
Retomando la introducción: en junio teníamos modelos que se desempeñaban tan bien como un adolescente inteligente, ahora tenemos herramientas de bajo costo tan potentes como un doctor en física, química o biología y como un desarrollador de software experto (en adición a lo que ya sabían hacer).
De este análisis inicial se desprenden algunas reflexiones que quiero compartir.
El marcado avance de los LLMs está determinado por tres factores:
capacidad de cómputo, es decir, la capacidad y número de los procesadores utilizados para entrenar los modelos
eficiencias algorítmicas la mayoría de las cuales permiten ganancias computacionales y, conjuntamente con los incrementos en capacidad de cómputo, es lo que se llama “cómputo efectivo”
liberación de restricciones (“unhobbling”) logradas mediante diferentes técnicas en el software y en los métodos de entrenamiento
En la siguiente gráfica están mapeados algunos de los modelos más conocidos, en función del cómputo efectivo utilizado en su entrenamiento:

Como varios de los fenómenos de la Era del Conocimiento, observen que el eje “Y” es logarítmico, con cada marca en ascenso representando dos órdenes de magnitud (ODM) adicionales (es decir un incremento de 100x). Hasta 2010, el incremento promedio fue de 0,14 ODMs por año; a partir de 2010 el promedio ha sido 0,4 ODMs por año (aprox. 4x).
En términos visuales, esta evolución se ve así1:
Video 1, creado con IA con una capacidad de cómputo base:
Video 2, creado con IA con una capacidad de cómputo 4 veces la base (0,4 ODMs):
Video 3, creado con IA con una capacidad de cómputo 32 veces la base (aprox. 1,5 ODMs):
La capacidad de cómputo la componen, de manera simple:
algoritmos (como lo mencionamos anteriormente)
procesadores (GPUs y TPUs) y capacidad de almacenamiento de información (memoria)
energía para operar data centers y para refrigerarlos
Mientras que el acceso a algoritmos es relativamente sencillo, con algunos desarrolladores incluso asumiendo una estrategia de publicarlos como código abierto, los componentes de hardware son marcadamente escasos, con mucha más demanda que oferta, y un poder concentrado en unos pocos jugadores como Taiwan Semiconductor Manufacturing Company (TSMC) el mayor fabricante de chips, diseñadores de procesadores como Nvidia (que tiene una participación de mercado de GPUs del 80%) y empresas de infraestructura en la nube como Google, Microsoft y Amazon.
Por consiguiente, no sorprende esto:

Sólo para cuantificar un poco esta “carrera por la inteligencia artificial” miren estos ejemplos:
para finales de 2024, Meta habrá comprado 350.000 H1000 (GPUs de Nvidia) por un valor que se estima en USD 14.000 millones
Amazon está adquiriendo data centers que incluyen su propia planta nuclear
Kuwait está desarrollando un mega data center, con 700.000 GPUs (el doble que Meta)
se rumora que OpenAI y Microsoft están trabajando en desarrollar un cluster de procesamiento de USD 100.000 millones para el 2028
La hipótesis de muchos, que luego podremos discutir en mayor profundidad, es que la IA implica un cambio de paradigma muy positivo para el bienestar de toda la humanidad. Sin embargo, la intensidad en el requerimiento de capital y la concentración en la oferta de sus componentes esenciales proponen unos retos económicos y geopolíticos delicados.
No puedo evitar pensar que nuestras economías latinoamericanas están mal posicionadas para no quedar, nuevamente, subordinadas a poderes lejanos en esta nueva fase de cambio.
Pienso, por una parte, que nuestra base empresarial, por la limitada experiencia y conocimiento, que inducen a la aprehensión, tendrá más limitado acceso a las herramientas de automatización que se desarrollarán integrando estas tecnologías, generando una mayor brecha de productividad con respecto a las economías americana y china que tienen cierto acceso privilegiado.
Adicionalmente, la soberanía de los países más vulnerables se deteriorará al no controlar su propio destino tecnológico. Piensen qué pasa cuando la disponibilidad y efectividad de los sistemas de defensa, de votación, de control del sistema energético o de salud, dependen de un país amigo, enemigo, o de una empresa cuyos intereses no necesariamente se alinean con los de nuestros ciudadanos. Esta realidad es perfectamente factible si los proveedores de las tecnologías del momento son unos pocos.
Si bien no conozco ninguna empresa latinoamericana que esté correctamente posicionada para ser un jugador relevante en los componentes de software y hardware que determinarán al ganador en esta carrera, se me ocurren que aún tenemos unos roles para jugar.
Leopold Aschenbrenner estima que si la expansión de la capacidad de cómputo continua con la tendencia de los años recientes, en 2030 consumirá 4x la capacidad actual de manufactura de chips de TSMC con una inversión en los trillones de dólares anuales y consumirá el 10% de la actual capacidad de generación de electricidad de Estados Unidos, 100 GW, unas 6 veces la capacidad instalada actualmente en Colombia.
Acá no tenemos el capital para ser los dueños de estos centros de cómputo, pero tal vez sí podamos ser sus anfitriones, si aprendemos a aprovechar nuestras ventajas competitivas naturales, en abundancia de agua, para refrigerar, y luminosidad para instalar generación fotovoltaica. El Plan Energético Nacional 2020-2050, ¡identificó en 2019 que Colombia tiene un potencial de 1.200 GW de energía solar! Incluso con un margen de error del 90%, seríamos la potencia mundial del procesamiento de datos para inteligencia artificial.
Adicionalmente, recordemos que ahora ChatGPT-o1 desarrolla software como un experto, usando instrucciones en lenguaje natural. Aunque esta innovación es relativamente nueva, observen lo que está pasando con el empleo de desarrolladores de software:

Herramientas como ChatGPT-o1 cierran la brecha de conocimiento entre una persona que sabe leer y escribir y un desarrollador de software. Esto hace que la idea de generar “empleo” rápido formando desarrolladores de software en meses, sea una estrategia finita. La mentalidad debe ser la de empoderar a las personas para que creen soluciones digitales, utilizando los LLMs como asistentes inteligentes. La formación que proveen la mayoría de los “coding schools” debe re-enfocarse a enseñar cómo identificar oportunidades de negocio, utilizar los LLMs para crear soluciones digitales y crear, crecer y retener audiencias/clientes. Esto es libertad de conocimiento y una ruta a la libertad económica.
Definitivamente no hay disculpas.
Por último: es crucial un sentido de urgencia. Cuando Leopold Aschenbrenner publicó Situational Awareness en junio, tenía total incertidumbre sobre cuándo los modelos podrían desempeñarse bien en las pruebas GPQA. Esto ocurrió en menos de tres meses. Como hemos dicho en el pasado, nuestro cerebro no procesa bien los comportamientos exponenciales, como el que estamos experimentando actualmente.
Los gobiernos piensan de una forma local, pequeña, sin consciencia alguna de la división que estas tecnologías van a crear entre “ellos” y “nosotros”. Aunque, por un lado, muchos gobiernos latinoamericanos han declarado la guerra al capitalismo y a la libertad económica, nunca en nuestra historia habíamos tenido tanto dominio del conocimiento y de la capacidad de generar riqueza, a tan bajo costo.
El futuro nos puede llegar más rápido de lo que creemos y tenemos una opción: construir el futuro con optimismo y contundencia o quedarnos anclados en las limitaciones del pasado e, incapaces de aprender de nuestra historia, quedarnos condenados a repetirla.
Eso es todo por hoy. Gracias por leer, comentar y compartir.
Camilo
Que bello es leerte Camilo, gracias por todo el contenido de tan alto valor, espero pronto otro episodio en 10AM
Qué potencia de artículo. Esto tiene que llegar a la mayor cantidad de personas. Realmente espectacular.